Automated and scalable predictive modeling in drug discovery with cloud computing, micro-services and Big Data frameworks
Drug discovery is facing challenges in data management and analysis due to increased throughput of data-generating experiments, such as high-throughput biological in-vitro assays. At the same time, international consortia and pre-competitive alliances have established large knowledge bases that open up for opportunities for computational modeling to aid the drug discovery process with decision aid, e.g. when prioritizing drug leads, assessing the toxicity of chemical substances, and predicting efficacy and secondary effects of molecules. Such modeling is an important task in the drug discovery pipeline, but the increasing data sizes makes predictive modeling challenging and in many cases require new methods and high-performance e-infrastructures. Also, there is a need to automate such modeling, compared to current practice where models are being developed manually and seldom kept up-to-date.
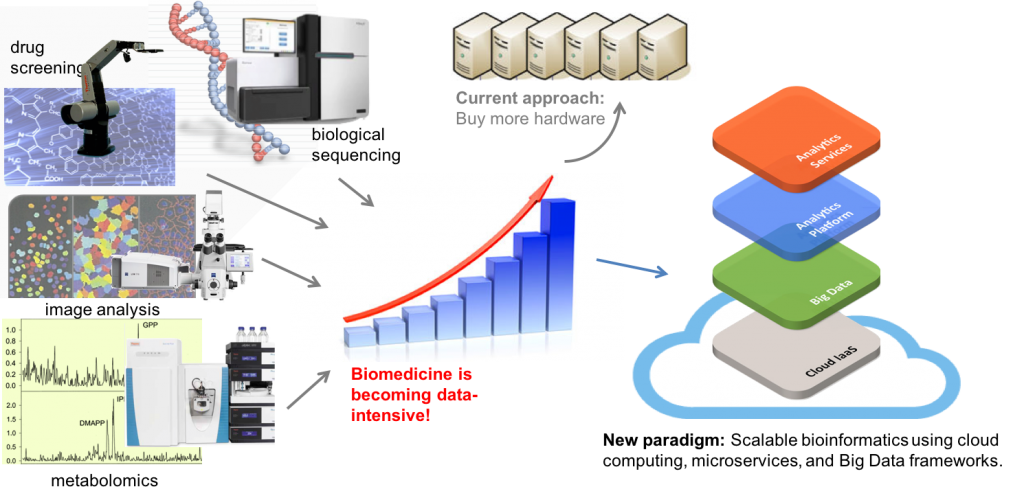
Aims
In this project we develop methods for predictive modeling of large-scale pharmaceutical problems that require distributed or high-performance computing. Problems include ligand-based modeling in predictive toxicology and metabolism, target-based profiling for secondary pharmacology, and structure-based methods for scalable molecular docking and virtual screening. The project is propelled by industrial use cases and carried out in collaboration with partners including AstraZeneca R&D, UCB, Douglas Connect Gmbh, SweTox, and connected to the international consortia OpenTox and IMI OpenPhacts. A key aim of the project is to enable large-scale predictive modeling with valid confidence measures, improving applicability and trust in predictive modeling of pharmaceutical problems.
Methods
We develop and apply methods for large-scale distributed machine learning using Big Data analytics frameworks such as Apache Hadoop and Spark, and deploy these on high-performance as well as public and private cloud computing and IaaS resources including SNIC Science Cloud and Google Cloud Platform. To address automation and reproducibility we use and develop scientific workflow systems such as SciLuigi (https://github.com/pharmbio/sciluigi) and SciPipe (https://github.com/scipipe/scipipe). We also develop and use micro-service based architectures deployed on cloud resources, orchestrated with software container orchestration frameworks Kubernetes and Mesos, to enable scalable and interoperable bioinformatics data analysis. A key focus of the project is scalable machine learning methods with valid confidence measures based on Conformal Prediction theory, and to apply these to problems in drug discovery to improve reliability and reduce costs in the drug discovery process. We make all methods and models publicly available as open source and easy consumable as cloud services, as well as via our graphical workbench Bioclipse (www.bioclipse.net).
Research group
PI:Assoc. Prof. Ola Spjuth
Dept. of Pharmaceutical Biosciences and Science for Life Laboratory, Uppsala University
Jonathan Alvarsson, Samuel Lampa and Valentin Georgiev
Dept. of Pharmaceutical Biosciences and Science for Life Laboratory, Uppsala University
Lars Carlsson and Ernst Ahlberg
AstraZeneca R&D
Links and references
Selected publications:
O. Spjuth, E. Bongcam-Rudloff, G. C. Hernandez, L. Forer, M. Giovacchini, R. V. Guimera, A. Kallio, E. Korpelainen, M. Kandula, M. Krachunov, D. P. Kreil, O. Kulev, P. P. Labaj, S. Lampa, L. Pireddu, S. Schönherr, A. Siretskiy, and D. Vassilev
Experiences with workflows for automating data-intensive bioinformatics
Biology Direct. 2015 Aug 19;10(1):43
M. Capuccini, L. Carlsson, U. Norinder and O. Spjuth
Conformal Prediction in Spark: Large-Scale Machine Learning with Confidence
2015 IEEE/ACM 2nd International Symposium on Big Data Computing (BDC), Limassol, 2015, pp. 61-67
E. Ahlberg, O. Spjuth, C. Hasselgren, and L. Carlsson
Interpretation of Conformal Prediction Classification Models
Statistical Learning and Data Sciences, vol. 9047 of Lecture Notes in Computer Science. Springer International Publishing, 2015, pp. 323–334
B. T. Moghadam, J. Alvarsson, M. Holm, M. Eklund, L. Carlsson, and O. Spjuth
Scaling predictive modeling in drug development with cloud computing
J. Chem. Inf. Model., 2015, 55 (1), pp 19-25