NoSQL Approach to Large Scale Analysis of Persisted Streams
In the area of large scale storing and analysis of big data poses some of the unique challenges for the traditional approach of utilizing legacy data storage systems.
In our industrial collaboration, including Bosch Rexroth – Hägglunds, Volvo Construction Equipment and Sandvik Coromant, a set of real world application scenarios have been defined, which involve analyzing data logs from industrial equipment. Specifically in the Hägglund scenario, an industrial equipment is powered through one or several hydraulic power systems each equipped with a set of sensors measuring various physical properties like pressures, power consumption, temperatures, etc. For a set of hydraulic power systems, these sensors generate large amounts of data that represent the operational state of the power system. The aim is to provide continuous operation by automatic monitoring and analysis of these sets of large-scale sensor data and avoiding unplanned interruptions.
A potential problem for analyzing this type of large-scale data generated at high rates is that the relational databases are not designed to handle these kinds of modern applications. Nevertheless, the analysis of large-scale data sets is becoming an integral part of contemporary e-science applications.
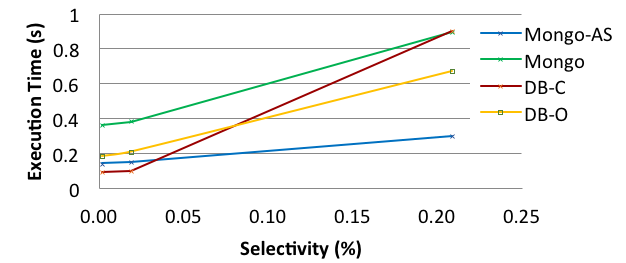
Performance comparison of state-of-art RDBMS and NoSQL data stores for a typical analytical query.
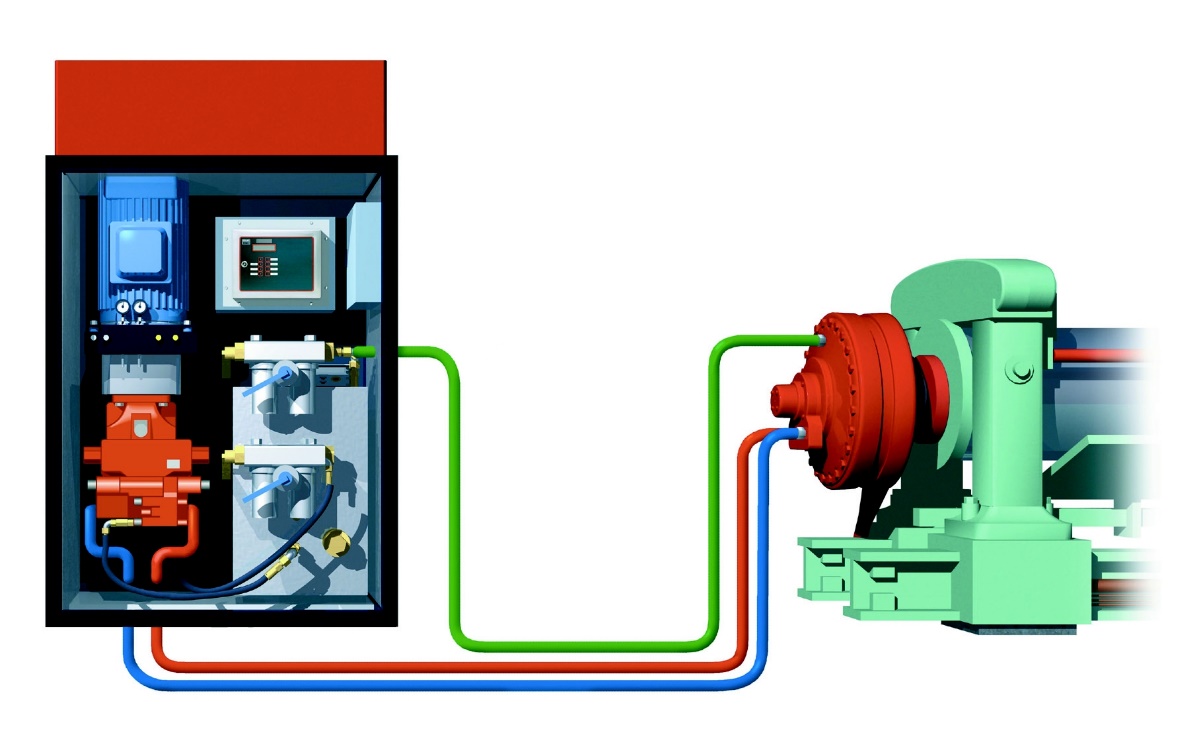
An example of a hydraulic power system.
Aims
The contemporary state-of-the-art NoSQL data stores are designed to handle the large scale archiving of data from e-science applications. The aim of the project is to investigate to what degree the state-of-the-art NoSQL data stores can achieve high performance persisting and large-scale analysis of big data to support real e-science applications such as found in the scenario of Hägglunds and others.
Methods
The project is currently developing a comprehensive benchmark utilizing legacy data storage systems as well state-of-the-art NoSQL data stores to persist and analyze large scale data from our real-world industrial applications. The benchmark will investigate to what degree a state-of-the-art NoSQL data store can achieve high performance persisting and large-scale analysis of data logs. The benchmark will serve as basis for investigating query processing and archiving of large-scale data. The research direction of the projects also concentrates on developing methods for scalable and extensible processing of queries analyzing different kinds of distributed data in terms of semantic ‘NoSQL’ data representations. Of particular interest is scalable processing of high-level queries analyzing high-volume data streams. Our strategy is to develop distributed execution strategies in an extensible platform where external systems, algorithms, and data managers can be plugged-in. This generic approach is expected to provide a seamless analysis of large-scale data not only of our current industrial scenarios but also in future e-science applications.
Research group
PI: Dr. Kjell Orsborn, Uppsala University
Prof. Tore Risch, Uppsala University,
PhD stud Khalid Mahmood, Uppsala University
Links and references
- Mahmood, T.Risch, and M.Zhu: Utilizing a NoSQL Data Store for Scalable Log Analysis, presented at 19th International Database Engineering & Applications Symposium, Yokohama, Japan, July 13-15, 2015.
- Mahmood, T.Truong, and T.Risch: NoSQL Approach to Large Scale Analysis of Persisted Streams, 30th British International Conference on Databases, Edinburgh, Scotland, July 6-8, 2015.
- Zhu, K.Mahmood, and T.Risch: Scalable Queries over Log Database Collections, 30th British International Conference on Databases, Edinburgh, Scotland, July 6-8, 2015.